| Products | Support | Download | Contact | |||||
![]()
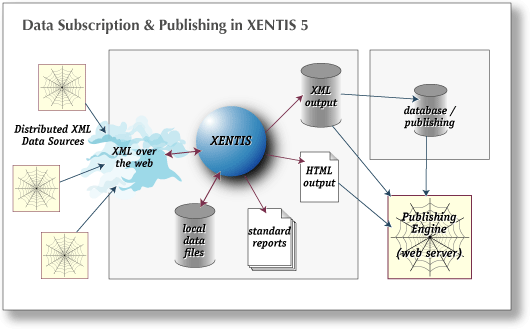
XENTIS Version 5 can now reach out to web servers which publish XML data sources and use those data sources as files in reports... As far as XENTIS is concerned: the entire Web is now an indexed file!
(In fact, one of the first test reports written reached out over the internet to an RSS feed to provide a list of the current news headlines.)
This revolutionizes the way that data mining and report generation is done with not only XENTIS but with OpenVMS. Essentially, XENTIS now incorporates its own HTML client. This means that regardless of the platform that the data is published on (SQL Server/Internet Information Server, Oracle/Apache/Tomcat), provided the information is published in a standards-compliant fashion, XENTIS on OpenVMS can now be used to generate reports on demand, in real-time. If you have a web server accessible from your OpenVMS system (either running on it or via a network share), you can have XENTIS generate its output in XML format and in turn make that information accessible the same way.
In the old days, if you needed to generate a report with data being generated in other applications on other platforms:
At this point you could run your report on it. Prior versions of XENTIS had the ability to produce reports in HTML format, but if you wanted to integrate the output into a database-driven publishing system, your best route was to use Model to produce tab-delimited output and run another script to import the data into the publishing system.
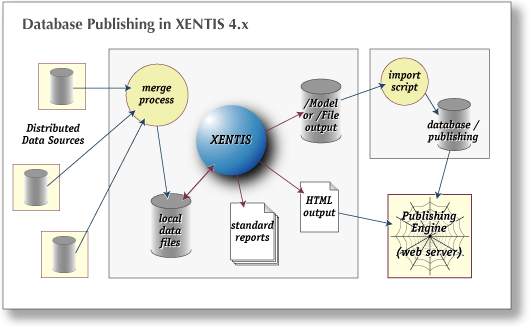
Among the problems with this approach are:
For users familiar with the way that XENTIS works, it's as simple as this sounds: you create a Dictionary definition for the data source, and simply use it as an indexed file. You can also create XML output based on that same dictionary definition.
Surprisingly, it turns out that some of the issues which might be expected to be problematic either go away or turn out to have rather earthshaking positive impacts:
It is the nature of XML that fields can occur in any order, and can be any length. In order to make this work with XENTIS you just define the fields you need (at the maximum length you expect): the technical solution turns out to have inherent practical benefits: you just define the fields you need.
Simple: What you name the "file" in XENTIS Dictionary is some arbitrary XML tag which corresponds to a record; what you name the fields are other XML tags which are contained within the record identified by the "file". Anything else in the data source is ignored. (We know we'll have to provide further examples of this. We also acknowledge that it is possible to have cases where this sort of simplistic mapping won't work, although early indications are that in practice the "keep it simple" paradigm does apply in the field.)
For instance all RSS feeds will be the same, so all RSS feeds will have the same XENTIS file name. Actual/generic syntax doesn't work so well with URLs (the actual file is specified in XENTIS Dictionary as a URL).
Remember that Web/XML data sources were implemented as indexed files? The way that this is accomplished is to allow parameter substitutions into the file's URL. It turns out there is no reason this has to be limited to CGI parameters: any part of the URL can be substituted. So different data sources are referenced with different parameters; old-school folks will recognize here the concept of file prefixes, although for the purposes of Web/XML data sources these are now specified in the key building section of the report definition.
"The web is an indexed file" may be reasonable for a primary file, but there's little doubt the performance could be expected to be predictably horrid for secondary files in cases where a single query is sent and retrieves a single record; some such reports will need to be restructured, or may not be possible at all (on the other hand people working with web-based systems today probably won't notice any impacts at all, because they lack something to compare to). But something new is afoot: given that the data sources conform to the same data standard and that the URL is part of the index, and that sufficient information is available in the primary file (or some other file) to index appropriate URLs, you can now reach out to entirely different servers in real-time for the information associated with different records in the primary file... which creates data mining possibilities which were inconceivable before... such as that "top news stories" report mentioned at the beginning of the article.
| © 2020 GrayMatter Software Corporation | Privacy policy | Terms of use |